Wanneer je het warehouse als enige bron van waarheid binnen de organisatie inzet, kun je er ook operationele applicaties op laten draaien: documenten matchen, statussen synchroniseren, beslissingen automatiseren op basis van data die in het warehouse staat. Hieronder een voorbeeld uit onze eigen praktijk, een email-archiveringsapplicatie die we voor Moovle hebben gebouwd.
Korte definitie nodig? Lees eerst wat data warehousing precies is.
Wat dashboards en automatiseringen gemeen hebben
Een dashboard heeft schone, samengevoegde data nodig. Een geautomatiseerd proces (bijvoorbeeld een script dat facturen archiveert of documenten aan projecten koppelt) heeft die data even hard nodig. Toch worden dashboards en automatiseringen in de meeste organisaties compleet verschillend ingericht.
- Dashboards krijgen een data warehouse: één centrale opslag waar alle bronnen samenkomen.
- Automatiseringen worden gebouwd op ad-hoc scripts die data ophalen uit een SharePoint-map, een Excel-bestand, of een API-call naar een ander systeem.
Het gevolg is voorspelbaar. De rapportages blijven kloppen, terwijl automatiseringen omvallen bij elke verandering in een bron. Dat hoeft niet zo te zijn. Hetzelfde warehouse dat de dashboards voedt, kan ook de automatiseringen dragen, als je er bij het ontwerp rekening mee houdt.
De eerste versie: zonder data warehouse
Bij Moovle hadden we de opdracht om PDF-bijlagen uit binnenkomende emails te koppelen aan het juiste project. Per email zat er soms één document in, soms vijf. De ene email vermeldde een keurig project-ID, de andere alleen een factuurnummer met een typo of een impliciete verwijzing. Op basis van die match moesten de bestanden in de bijbehorende SharePoint-map worden gezet.
Het e-mailarchief rondom verkoop facturatie telt inmiddels zo’n 22.000 berichten. Alleen die bestaande bak handmatig wegwerken kost bij vijf minuten per email al ruim 1.800 uur, meer dan 200 werkdagen. Archiveren met de hand was daarmee nooit een serieuze optie; in de praktijk gebeurde het sporadisch tot helemaal niet.
De eerste versie van de automatisering hadden we gebouwd voordat er een warehouse was. Dat had drie consequenties:
- Matches verifiëren was bijna onmogelijk. We hadden geen referentielijst van alle projecten, dus we moesten erop vertrouwen dat de uitgelezen ID daadwerkelijk klopte met een bestaand project. In de praktijk lieten we matches doorlopen die later vals bleken.
- We leunden op gedeelde Excel-bestanden voor de status van projecten en de voortgang van het archiveringsproces. Eén verkeerde wijziging in zo’n bestand brak de hele flow, en niemand kon achterhalen wie wat had aangepast.
- SharePoint was tegelijk de eindbestemming én de bronwaarheid. Als SharePoint iets verkeerd toonde, hadden we geen manier om dat te ontdekken. Geen onafhankelijke check, geen audit-log.
Het werkte, op zijn manier. Maar elke keer dat iemand op vakantie ging of een sjabloon aanpaste, hielden we ons hart vast.

Het warehouse kwam pas later
Voordat Moovle een warehouse had, las Power BI rechtstreeks uit het ERP. Die directe koppeling was fragiel: dashboards gaven errors bij het verversen, en de frequentie waarmee we data konden ophalen lag te laag om operationele beslissingen op te baseren. Daar kwam bij dat Moovle hun infrastructuur graag spreidde over meerdere systemen, en hun data bewust op een Europese omgeving wilde houden.
We hebben daarom een MySQL warehouse opgezet op een Europese server bij Trans-ip, in eigen beheer bij Moovle. De data lag daarmee op een door Moovle gecontroleerde infrastructuur, en dichtbij huis.
“We vinden het in deze tijd een risico om al onze data op buitenlandse servers te hebben staan. Daarom voelt het goed om een back-up van onze data nu hier om de hoek te hebben.”
— Wim Versluis – Manager Operations, Process & IT
Power BI las vanaf dat moment uit het warehouse in plaats van direct uit het ERP. De refresh-errors verdwenen en de update-frequentie ging omhoog.
“Met het door Newbit ingerichte data warehouse kunnen we veel vaker en sneller data synchroniseren tussen de bronsystemen en bijvoorbeeld onze BI-omgeving.”
— Wim Versluis – Manager Operations, Process & IT
Een tijdje later kwam de archiveringsapplicatie aan de beurt voor een update. Daar kwam de vraag boven: waarom zou die app op losse Excel- en SharePoint-bestanden blijven leunen, terwijl alle data die hij probeerde samen te brengen, al schoon en gestructureerd in het warehouse stond?
Tweede ontwerp: warehouse als backbone
We hebben de archiveringsapplicatie opnieuw ontworpen, dit keer met het warehouse als centrale databron. Dat veranderde drie dingen.
- Verificatie werd mogelijk. Voordat de automatisering een document koppelde aan een project, controleerde hij de uitgelezen ID tegen de projectlijst in het warehouse. Bestaat dit ID? Welke factuurnummers horen erbij? Welke schrijfvarianten gebruiken klanten? Als de match niet sluitend was, ging het systeem naar handmatige beoordeling in plaats van blind door te lopen. Inmiddels komt vrijwel iedere mail tot een sluitende match, en bij de uitzonderingen toont het systeem precies welke documenten nog wachten zodat ze in een paar klikken op de juiste plek belanden.
- We zagen wat er ontbrak. Het warehouse bevat een volledige lijst van projecten. Dat opent een omgekeerde view: van welke projecten hadden we nog geen documenten ontvangen, en welke verwachtten we wel? Daarmee konden we signalen geven over openstaande zaken in plaats van alleen op binnenkomende mails te reageren.
- De infrastructuur paste beter bij wat we deden. Een warehouse is gebouwd op transactionele consistentie, historische opslag en meerdere lezers en schrijvers naast elkaar. Excel is dat niet, en SharePoint is bedoeld als documentopslag, niet als operationele database. Een direct voordeel was dat we automatisch een audit-log opbouwden van iedere verwerkte email: welke bijlagen erin zaten, in welke archiefmap ze zijn beland, en wanneer.

Een dashboard over de automatisering zelf
Omdat de applicatie iedere verwerkingsstap wegschrijft naar het warehouse, ontstaat daar een tweede dataset. Niet over projecten en documenten, maar over het functioneren van de automatisering. We hebben daar een dashboard op gebouwd dat de systeembeheerder van Moovle een live beeld geeft van:
- hoeveel emails zijn verwerkt en met welk resultaat,
- welke projecten documenten missen,
- hoe vaak de verificatie een correctie aanbracht op de eerste extractie,
- trends in volume en kwaliteit van inkomende documenten.
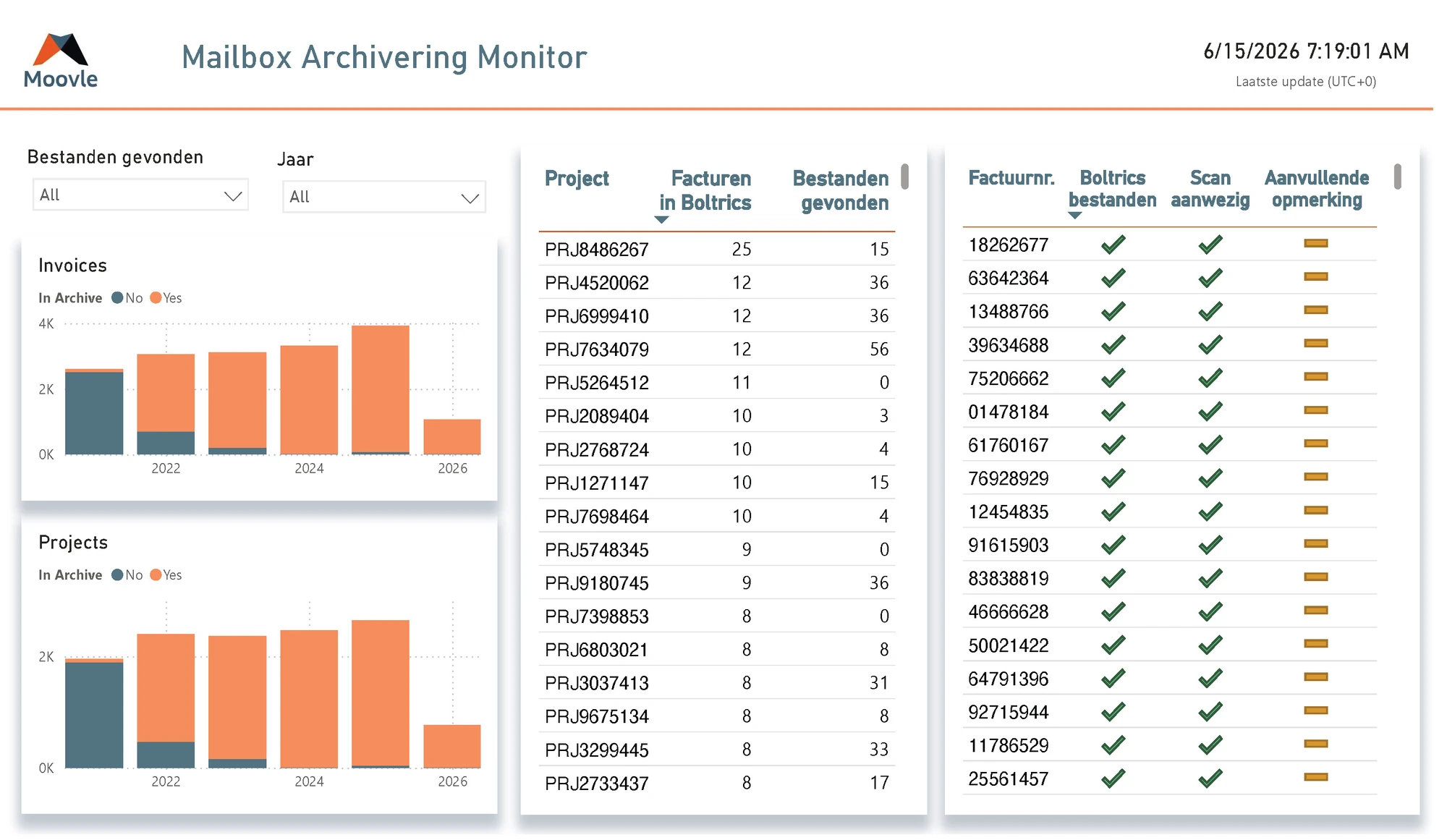
De structuur is daarmee in zekere zin circulair. Het warehouse levert de automatisering context (welke projecten bestaan, welke nummering ze hanteren, welke status ze hebben), de automatisering schrijft haar verwerkingsstappen terug naar het warehouse, en die data voedt vervolgens een dashboard dat zowel de klant als ons inzicht geeft in hoe het proces loopt. We hadden dat dashboard niet vooraf bedacht. Het rolde uit het ontwerp omdat alle data nu eenmaal op één plek beschikbaar was.
Wanneer deze aanpak voor jouw organisatie relevant is
Een paar signalen waaraan we deze situatie meestal herkennen:
- Geautomatiseerde processen leunen op Excel-bestanden of SharePoint-structuren die niemand meer durft aan te raken.
- Rapportages laten andere cijfers zien dan de operationele systemen, en niemand weet precies waarom.
- Bij personeelswissels valt er telkens een stuk automatisering om.
- Je weet niet precies wat je automatiseringen doen, of hoe vaak ze daadwerkelijk slagen.
- Er staat al een data warehouse voor BI, maar het wordt puur voor rapportage gebruikt.
Vooral dat laatste komen we regelmatig tegen. De investering in een warehouse is dan al gedaan, het systeem doet alleen niet wat het zou kunnen doen.
Hoe je hieraan begint
We werken meestal volgens drie principes.
Eerst de data inventariseren, dan pas de automatisering ontwerpen. Voordat we iets bouwen, brengen we in kaart welke entiteiten in de organisatie bestaan (klanten, projecten, producten, contracten) en wat of wie voor elk daarvan de bron van waarheid is. Pas daarna bepalen we waar het warehouse die rol overneemt, en waar het juist afleest.
Schrijf vanuit automatiseringen terug naar het warehouse. Een warehouse dat alleen wordt gelezen, is feitelijk een grote leeszaal. Pas wanneer applicaties er ook naar terugschrijven (status van een document, uitkomst van een verificatie, foutmelding van een externe API) wordt het een operationele backbone. Begin klein, met de processen waar een audit-log of historische log meteen waarde oplevert.
Bouw vroeg in het traject een operationeel dashboard. Niet pas wanneer de automatisering af is, maar al tijdens de bouw. Zo zie je tijdens het ontwikkelen waar het systeem blinde vlekken heeft, en kun je bijsturen voordat het in productie staat.

Tot slot
Een data warehouse hoeft geen exclusief BI-instrument te zijn. Dezelfde infrastructuur die rapportages mogelijk maakt, kan ook operationele automatiseringen dragen, op voorwaarde dat je er bij het ontwerp rekening mee houdt. Bij Moovle leverde die combinatie een archiveringsproces op dat aanmerkelijk betrouwbaarder is dan de eerste versie, plus een dashboard waarmee de beheerder direct kan zien wat het systeem doet.
Het patroon herhaalt zich bovendien. Email-archivering is voor Moovle een van meerdere processen die op het warehouse leunen; een vergelijkbare aanpak loopt nu voor terminal-data, die geautomatiseerd in hun ERP-systeem wordt getoond.
“Het data warehouse geeft ons de mogelijkheid om bijvoorbeeld terminal-data geautomatiseerd in ons eigen ERP-systeem te tonen.”
— Wim Versluis – Manager Operations, Process & IT
Werk je met automatiseringen die te vaak omvallen, of staat er een data warehouse dat niet veel meer doet dan dashboards voeden? Neem contact op, dan kijken we samen waar een single source of truth iets voor je kan betekenen.
“Archivering is niet per se het leukst om je mee bezig te houden. Daarom ben ik blij dat al onze documenten nu geautomatiseerd en geordend worden opgeslagen.”
— Wim Versluis – Manager Operations, Process & IT

